dev @ purchease
comment nous codons chez purchease
Article ICDAR 2019
Publié par anh le 15/06/2019 - r&dIntro
Pour résoudre les différents problèmes liés à l’extraction structurée issues de documents capturés par mobile, nous avons recours le long de notre chaîne de traitement à des algorithmes mettant en oeuvre des réseaux de neurones. Ces algorithmes ont la particularité d’être efficaces, robustes a l’overfit mais présentent un souci majeur : ils nécessitent un large volume de données d’apprentissage annotés, souvent de l’ordre de la centaine de milliers d’exemples. L’obtention d’une base annotée est particulièrement coûteuse car elle fait appel à une expertise humaine qui jugera sur un grand nombre d’exemples du résultat attendu sur chacun.
ICDAR
ICDAR (International Conference on Document Analysis and Recognition) c’est comme son nom l’indique… En pratique, des chercheurs du monde entier soumettent leur article de recherche dans le domaine de l’extraction de document, et ceux plebiscités par les relecteurs sont présentés lors d’un conférence qui se tient tous les deux. J’ai eu la chance d’y aller avec un premier article en 2017 ( c’était à Kyoto). Un deuxième article a été selectionné pour l’édition 2019. C’est celui dont parle ce billet, et j’ai eu la chance de pouvoir le présenter à Sydney.
ICDAR (International Conference on Document Analysis and Recognition) c’est comme son nom l’indique… En pratique, des chercheurs du monde entier soumettent leur article de recherche dans le domaine de l’extraction de document, et ceux plebiscités par les relecteurs sont présentés lors d’un conférence qui se tient tous les deux. J’ai eu la chance d’y aller avec un premier article en 2017 ( c’était à Kyoto). Un deuxième article a été selectionné pour l’édition 2019. C’est celui dont parle ce billet, et j’ai eu la chance de pouvoir le présenter à Sydney.
La publication en résumé
Principe
Nous proposons une méthode visant à générer des images synthétiques qui ressemblent aux images réelles (capturées par des appareils mobiles). Nous considérons que l’image du document est une combinaison de 2 éléments :
- le contenu (le texte, la police du texte)
- le style (des déformations, bruits)

En extrayant le style des images réelles et appliquant à une image binaire, nous pouvons générer des images réalistes.
Nous nous basons sur les méthodes de GAN (Generative Adversarial Networks), plus précisément, les modèles Dual-GAN et MUNIT .
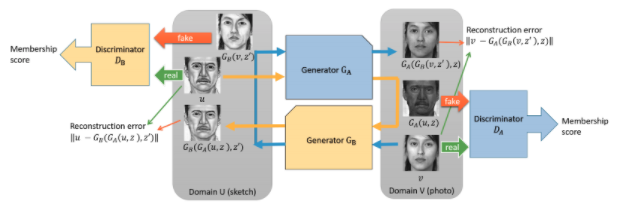
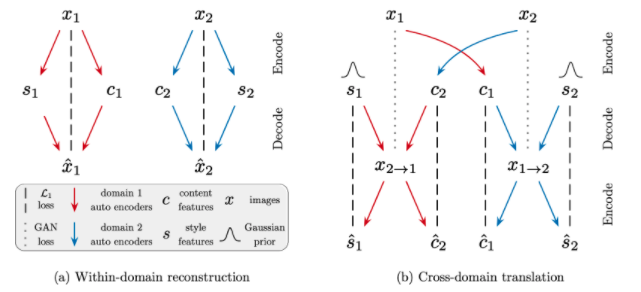
Le principe général est le suivant : un réseau de neurone est entrainé à générer des images synthétiques : il utilisera pour cela le résultat de l’apprentissage construit sur des images réelles. L’autre réseau de neurones est entrainé à discriminer les images synthétiques des images réelles. L’entrainement de la conjonction des deux converge vers des images très réalistes.
Résultats
Voici les résultats d’image synthétiques :
- Ligne A : une image binaire ‘modèle’
- Ligne B : une image synthétisée par MUNIT
- Ligne C : une image synthétisée par Dual-GAN


Validation
On a obtenu des jolies images… mais vont-elles nous être utiles ? On a fait tous ces efforts pour gagner des ensemble d’apprentissage pour l’OCR : en générant des images à partir du texte que l’on maitrise, on a bien des images de texte dont on connait le texte. Est-ce que ca marche ? Pour tester, onconstruit 3 ensembles : documents ‘naturels’ annotés, documents synthétiques seulement et mélange des deux à parts égales. On entraine ensuite le même système d’OCR avec ces trois ensembles d’entrainement et on compare les performances de ce qui deveint alors 3 OCRs différents :
| Ensemble de donneés | Taux de reconnaissance OCR |
|---|---|
| 100000 images ‘naturelles’ annotées manuellement | 82,2% |
| 100000 images ‘naturelles’ annotées + 100000 images synthétiques annotées automatiquement | 96.2% |
| 100000 images synthétiques annotées automatiquement | 73.0% |