dev @ purchease
comment nous codons chez purchease
PurchEase vs article de blog
Publié par david le 25/09/2020 - architectureIntro
On voit régulièrement des articles de blog traitant d’une question bien connue : digitaliser les tickets de caisse dans le but de suivre ses dépenses ou pour faire des notes de frais. Les articles se résument en général à l’approche suivante :
- pre-processing sur l’image
- appel à un OCR
- quelques regex
- ET VOILA
Cela construit l’idée recue selon laquelle le problème d’extraction de données des tickets est résolu : c’est faux. Certes les systèmes industriels comme celui de PurchEase suivent un déroulé assez similaire à ce qui est décrit ci-dessus, mais chacune des étapes ne peut se résoudre à quelques lignes de python ( ou autre ). Il s’agit bien de problèmes indépendants et complexes. Nous allons voir par la suite les écueils qui rendent la tâche complexe.
Idée reçue numéro 1 : un OCR fait le travail
L’erreur commune est de faire l’amalgamme entre entre OCR et extraction de document. Un OCR ( Optical Character Recognition ) est un systeme de reconnaissance de caractères : il identifie les zones de texte, et associe à l’image de mot leur contenu littéral. Prenons l’exemple d’un célèbre exemple d’OCR : le module dédié de GoogleVision. Voici ce qu l’on obtient en faisant un appel à son API :

Les zones sur lesquelles sont repérées le texte sont contourés en bleu. En vert est rendu le résultat de l’OCR. L’OCR a fini son travail. On a du texte et sa position. On est loin de savoir ce qui a été acheté !
Idée reçue numéro 2 : “si le document est de qualité médiocre… et bien tant pis !”
Comme annoncé plus haut, le processus d’extraction que nous utilisons n’est pas fondamentalement différent de la structure de nos blogueurs. En revanche, c’est la difficulté qui est sous-estimée. Pourquoi ? Pour être ROBUSTE à toutes les altération du document. Un OCR marche quasi parfaitement sur un document scanné, mais si on ambitionne de lire des tickets de caisse capturés par mobile, on se heurte a trois difficultés :
- le document original est fragile et il n’est pas envisageable de refuser un ticket à un utilisateur sous prétexte qu’il la mis dans sa poche

- la capture par mobile n’est pas aussi bien controlée que sous un scanner : dérives d’éclairage, de flou et contraintes liées au ratio du ticket posent de vrais problèmes

- les structures de ticket de caisse, sont très, très variables, parfois même difficiles à interpréter pour un oeil humain

Si les techniques triviales peuvent en effet lire des tickets de caisse a peu près correctement dans de bonnes conditions, on ne peut s’en contenter si on souhaite limiter les contraintes à l’utilisateur final.
Idée reçue numéro 3 : “un peu de preprocessing, quelques regex et c’est gagné”
Suivons désormais toutes les étapes nécessaires à l’extraction.
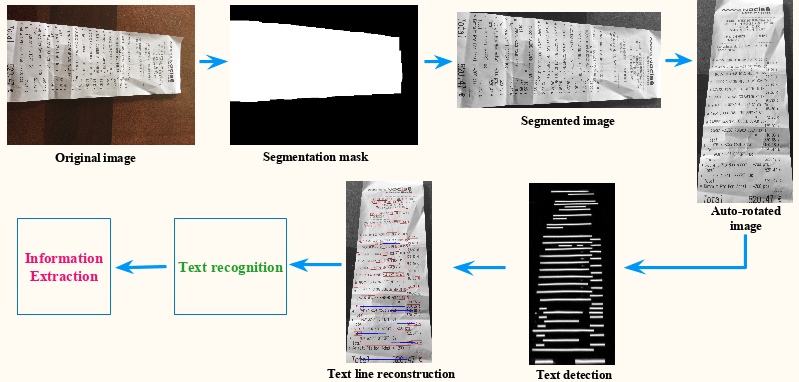
Segmentation et orientation
Le ticket est identifié par un réseau de neurones convolutif, et son orientation détectée par un second.
Detection
L’extraction des lignes est confiée à un nouveau réseau de neurones convolutif.

Reconstruction des lignes
Un autre problème épineux non résolu par un OCR est evidemment l’association des lignes. Bien entendu, problème trivial sur un document bien scanné, mais qui se complique sérieusement avec des tickets de caisse capturés par mobile.

Enfin on peut lire !
C’est seulement à l’issue de ces étapes que l’on va pouvoir passer à la reconnaissance de texte : là il s’agit d’OCR. Celui de PurchEase a été developpé en interne.

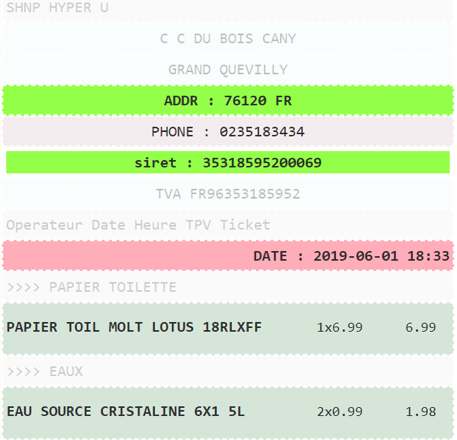
Structurer la donnée
Voilà, on a notre texte ! Il est temps de comprendre le contenu. Pour cela, on fera appel à un système de règles construit par notre expertise et analyse issues de notre expérience. D’un point de vue technique, on fear confiance aux fabricants de système de caisse pour faire l’hypothèse que la représentation des achats qui y figurent suit une grammaire régulière. Grâce à l’implémentation de parsers dédiés on sera capable de trouver la grammaire qui représente le mieux le contenu du ticket et de l’exploiter :
Conclusion
Nous avons finalement nous aussi écrit notre article de blog, avec des étapes similaires. En revanche, on peut difficilement se contenter de réunir le code en quelques lignes. En pratique, cette chaîne de traitement est distribuée sur plusieurs applications dédiées ( le code du traitement d’image est en C++, l’extraction de contenu en ruby). Cela pose également des questions d’architecture générale pour articuler tous ces services entre eux. Ce qui fera probablement l’objet d’un autre billet.